在2024年国际语音通信协会(ISCA)主办的全球旗舰语音会议Interspeech 2024上,由邹月娴教授带领的现代信号与数据处理实验室(下称ADSP实验室)的研究团队荣获显著成绩。Interspeech 2024共录用1029篇学术论文,评选出最佳论文(Best Paper Award)2篇和最佳学生论文(Best Student Paper Award)3篇。ADSP实验室21级辛逸飞同学为一作的论文“DiffATR: Diffusion-based Generative Modeling for Audio-Text Retrieval”荣获Interspeech 2024最佳论文奖(Best Paper Award);在香港中文大学攻读博士学位的ADSP实验室2023届毕业生杨东超为一作的论文“SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models ”荣获Interspeech 2024最佳学生论文奖(Best Student Paper Award);在约翰霍普金斯大学攻读博士学位的ADSP实验室2022届毕业生王赫麟为一作的论文“Noise-robust Speech Separation with Fast Generative Correction”荣获最佳论文提名奖(Best Paper ShortList)。这一系列研究成果和荣誉获得了语音科技界同行的高度评价与祝贺,充分彰显了ADSP实验室在语音技术前沿研究领域的影响力与贡献。
本次获得Interspeech 2024最佳论文的“DiffATR: Diffusion-based Generative Modeling for Audio-Text Retrieval”(下简称DiffATR)面向音频-文本检索(Audio-Text Retrieval, ATR)任务开展研究,是机器听觉领域的重要课题。ATR任务旨在输入单模态查询(text or audio query),从目标模态数据库中检索出语义相似的数据实例。ATR技术在深度学习时代取得了长足进步,但由于跨模态配对数据标注困难和缺乏超大规模训练数据集,ATR深度模型尚不能满足商业应用需求。在这项工作中,获奖论文创新地设计了DiffATR,一个基于扩散的音频-文本检索生成模型,为充分利用生成模型的强大能力和有效建模音频-文本联合概率提供了新框架。在主流标准数据集(AudioCaps和Clotho)上,DiffATR展示了卓越的域内数据集检索性能。实验结果也表明,在未采用域外目标数据集微调的情况下,DiffATR在域外数据上也保持了出色的检索性能。上述实验结果表明了DiffATR技术路线的有效性。DiffATR的探索性研究为基于生成式模型进一步提升ATR的性能提供了新的技术路径。

生成式DiffATR框架

DiffATR去噪模块
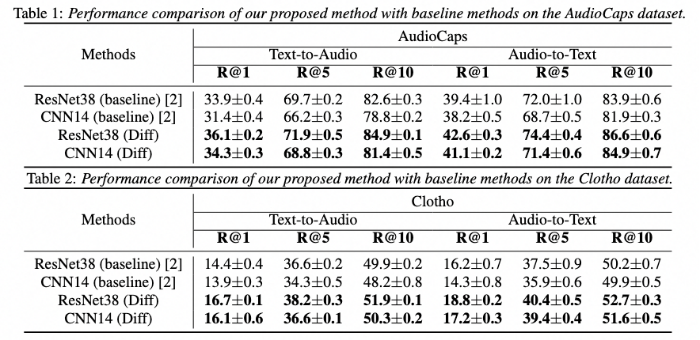
域内数据集检索实验结果
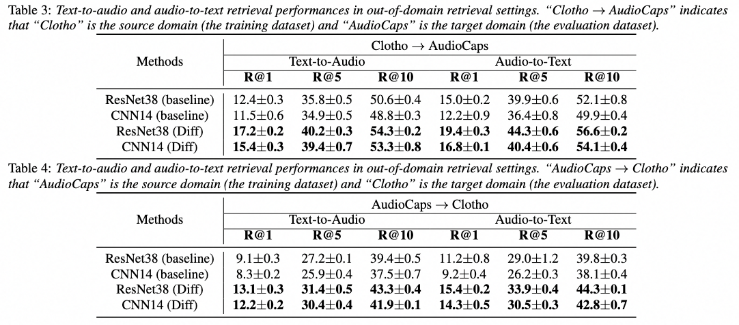
域外数据集检索实验结果
邹月娴教授带领的ADSP实验室语音小组一直积极参与语音技术领域前沿课题的研究,让机器听懂世界是大家共同的追求,推动AI赋能产业,解决行业痛点是ADSP实验室长期的奋斗目标。
ADSP实验室今日所取得的优秀研究成果,源于导师与学生间的密切协作,团队成员所秉持的坚韧不拔的研究精神、自由探索的学术态度和跨学科合作的开放理念。这种独特的科研氛围不仅激发了创新,更为实验室的持续进步奠定了坚实基础。
在Interspeech这一全球顶尖的语音技术会议上,ADSP实验室的亮眼表现不仅展示了团队在语音技术前沿研究领域的最新突破,更彰显北京大学深圳研究生院在前沿技术领域的国际影响力。这些成绩的取得无疑将激励ADSP语音研究团队继续在科技强国时代砥砺前行,为推动语音技术的发展和培养优秀专业人才做出更大贡献。


