大数据和人工智能与化学基因和材料基因的融合正推动生物医学和新材料的前沿科学发展。近年来,机器学习,尤其是深度学习,已经成为基于数据驱动的分子尺度发现化学基因和材料基因强大方法。2019年冠状病毒病(COVID-19)爆发一年后还没有特异性的有效药物,这提醒我们生物医药是复杂的前沿科学领域,有效的药物发现涉及一系列相关的分子特性,包括结合亲和力、毒性、分配系数、溶解度、药代动力学、药效学等等。对生物医药分子特性的实验测定是非常耗时和昂贵的。此外,涉及到动物或人类的实验测试会有道德问题的禁区。因此,大数据和人工智能的方法在许多情况下可以产生快速的结果而不严重牺牲准确性,其中最受欢迎的方法之一是定量结构活性关系(QSAR)分析,它假定类似的分子具有类似的生物活性和理化性质。尽管科研人员在预测分子性质的方向已经做了大量的工作,但各种分子性质的定量预测仍然是一个挑战。
近日,北京大学深圳研究生院新材料学院的潘锋团队与密歇根州立大学数学系的魏国卫教授合作,通过融合代数图论方法和Google开发的深度自注意力变换(Transformer)的机器学习方法提出和发展了一种新型的代数图辅助的双向转化器(AGBT)框架,实现基于小样本数据有效的定量预测分子特性。这一成果近期发表在《自然.通讯》(Algebraic graph-assisted bidirectional transformers for molecular property prediction. Nature Communications, 2021,12(1), 1-9.)。
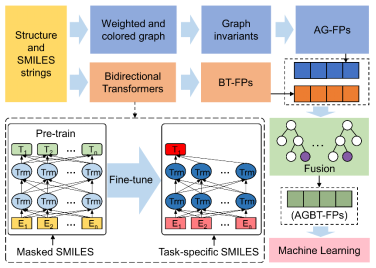
图1 代数图论方法辅助的双向转化器(AGBT)框架
通常深度学习方法需要大量的数据集来进行训练,在小型数据集上利用深度学习模型一般很难取得有效准确的预测。在化学中,通过实验或者第一性原理确定有标签性能的数据只占少数。团队发现化学中的分子性能预测极大依赖于分子描述符或分子表示法,拓展深度学习方法来产生高质量的分子描述符可以提升预测的准确性,包括运用自然语言处理(NLP)中自监督学习方法,大量无标签的语言数据可被用于“预学习”和用于模型的训练和预测,在生物医学方面运用分子的SMILES表示的化学语言,利用自然语言处理中的相关模型实现了基于自监督学习方法的预训练。团队在研究中发现基于SMILES数据的训练模型会丢失一些分子结构的三维信息,从而影响相应的分子描述符的质量,从而自主原创设计出一种基于代数图论辅助的深度学习框架(AGBT),这种方法既利用了Transformer这种深度学习方法将大量无标签的分子数据利用起来,又借助了代数图论的方法弥补了深度学习框架(Transformers)所遗失的一些三维信息,可以实现高质量的分子描述符的产生。这种分子描述符,对小数据样本的分子特征预测的能力有较高的提升,实现快速有效的定量的分子特性预测。

图2 一种元素特异性的多尺度加权彩色代数图论方法
此外,本工作利用代数图图论的方法,特别是特定元素的多尺度加权彩色代数图论方法,将三维分子信息嵌入图的不变量中,发展了代数图辅助的双向转化器(AGBT)框架,通过融合代数图论方法产生的分子描述符和Transformers产生的分子描述符表,实现与两种分子信息的互补。此外,借助各种机器学习算法,包括决策树、多任务学习和深度神经网络,实现下游任务中对分子特性的预测。本工作在八个分子数据集上验证了所提出的AGBT框架,涉及定量毒性、物理化学和生理学数据集。大量的数值实验表明,所发展的AGBT是一个高效的分子特性预测模型。
文章的第一作者是北京大学深圳研究生院新材料学院的博士研究生陈冬,通信作者是潘锋和魏国卫教授。感谢国家材料基因工程重点专项和广东与深圳科技项目的支持。
文章链接:https://doi.org/10.1038/s41467-021-23720-w


